 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMostly-Unsupervised Statistical Segmentation of Japanese Kanji Sequences
May 10, 2002
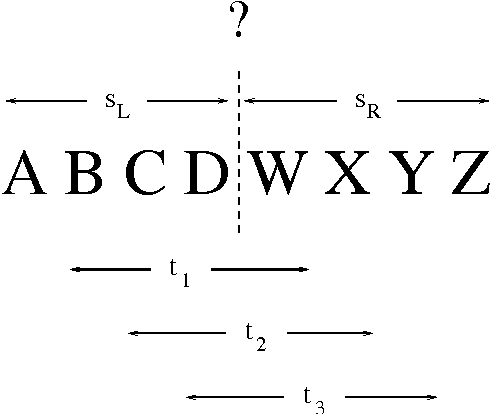
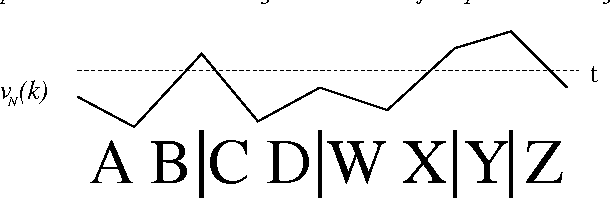
Given the lack of word delimiters in written Japanese, word segmentation is generally considered a crucial first step in processing Japanese texts. Typical Japanese segmentation algorithms rely either on a lexicon and syntactic analysis or on pre-segmented data; but these are labor-intensive, and the lexico-syntactic techniques are vulnerable to the unknown word problem. In contrast, we introduce a novel, more robust statistical method utilizing unsegmented training data. Despite its simplicity, the algorithm yields performance on long kanji sequences comparable to and sometimes surpassing that of state-of-the-art morphological analyzers over a variety of error metrics. The algorithm also outperforms another mostly-unsupervised statistical algorithm previously proposed for Chinese. Additionally, we present a two-level annotation scheme for Japanese to incorporate multiple segmentation granularities, and introduce two novel evaluation metrics, both based on the notion of a compatible bracket, that can account for multiple granularities simultaneously.
* 22 pages. To appear in Natural Language Engineering
Iterative Residual Rescaling: An Analysis and Generalization of LSI
Jun 17, 2001We consider the problem of creating document representations in which inter-document similarity measurements correspond to semantic similarity. We first present a novel subspace-based framework for formalizing this task. Using this framework, we derive a new analysis of Latent Semantic Indexing (LSI), showing a precise relationship between its performance and the uniformity of the underlying distribution of documents over topics. This analysis helps explain the improvements gained by Ando's (2000) Iterative Residual Rescaling (IRR) algorithm: IRR can compensate for distributional non-uniformity. A further benefit of our framework is that it provides a well-motivated, effective method for automatically determining the rescaling factor IRR depends on, leading to further improvements. A series of experiments over various settings and with several evaluation metrics validates our claims.
* To appear in the proceedings of SIGIR 2001. 11 pages